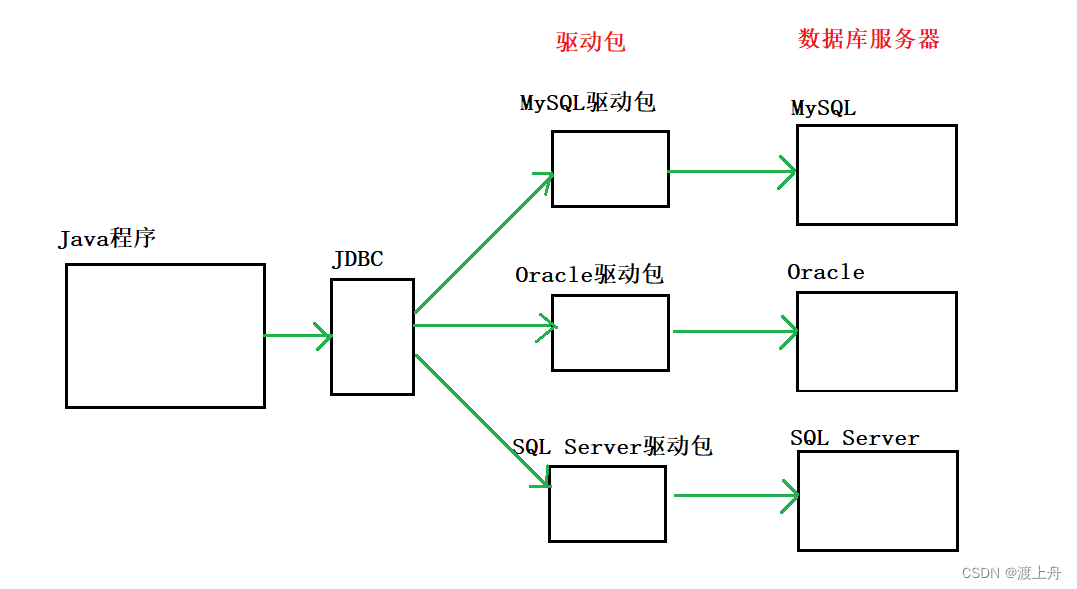
什么是pandas
Pandas是一个开源的第三方Python库,它从Numpy和Matplotlib的基础上构建而来,享有数据分析“三剑客之一”的盛名。Pandas已经成为Python数据分析的必备高级工具,目标是成为强大、灵活、可以支持任何编程语言的数据分析工具。
数据结构
Pandas中除了Panel数据结构,还引入了两种新的数据结构——Series和DataFrame,这两种数据结构都建立在NumPy的基础之上。
(1)Series:一维数组系列,也称序列,与Numpy中的一维array类似。二者与Python基本的数据结构list也很相近。
(2)DataFrame:二维的表格型数据结构。可以将DataFrame理解为Series的容器。以下的内容主要以DataFrame为主。、
(3)Panel:三维数组,可以理解为DataFrame的容器。
数据类型
Logical(逻辑型)
Logical又叫布尔型,只有两种取值:0和1,或者真和假(True和False)。逻辑运算符有:& (与,两个逻辑型数据中,有一个为假,则结果为假) , | (或,两个逻辑型数据中,有一个为真,则结果为真) ,not(非,取反)。
Numeric(数值型)
数值运算符有:+ -*和/。
Character(字符型)
字符型数据一般使用单引号(' ' )或者双引号(" ")包起来。
Python数据类型变量命名规则如下:
(1)变量名可以由a~z A~Z,数字,下划线组成,首字母不能是数字和下划线;
(2)大小写敏感,即区分大小写;
(3)变量名不能为Python中的保留字,如and continue lambda or等。
数据结构
数据结构是指相互之间存在的一种或多种特定关系的数据类型的集合。Pandas中主要有Series(系列)和Dataframe(数据框)两种数据结构。、
Series
Series(系列,也称序列)用于存储一行或一列的数据,以及与之相关的索引的集合。
from pandas import Series
x=Series(['a',2,'狗狗'],index=['a','b','c'])
print(x)
print(x['a'])
a a
b 2
c 狗狗
dtype: object
a
Series的index如果省略,索引号默认从0开始,也可以指定索引名。
为了方便后面的使用和说明,此处定义可以省略的index,也就是默认的索引号从0开始计数,赋值给定的index,我们称为索引名,有时也称为行标签。
补充:
dtype:object为列中的数据类型
数值类型:
int64:64位整数。
float64:64位浮点数。
int32, int16, int8:不同位数的整数,根据数据的大小和内存使用情况来选择。
float32:32位浮点数。
时间类型:
datetime64[ns]:用于存储日期和时间的数据类型,精度为纳秒。
timedelta[ns]:用于存储时间间隔的数据类型,同样精度为纳秒。
文本类型:
str:用于存储字符串数据。
类别类型:
categorical:用于存储分类数据的数据类型,可以有效地减少存储空间并提高性能。
稀疏类型:
sparse:用于存储包含很多零值的稀疏数据,可以减少存储空间。
其他:
bool:布尔类型,用于存储真/假值
当Pandas无法确定列中所有元素的共同数据类型时,它通常会默认将列的数据类型设置为object
那这个与上面的数据类型是什么关系呢?
在Pandas中,dtype(数据类型)与逻辑型、数值型和字符型这些概念是密切相关的。dtype是Pandas用来表示数据列中元素类型的一个属性,而逻辑型、数值型和字符型是这些数据类型中的具体分类。
相关功能函数
from pandas import Series
import pandas as pd
#定义序列
x=Series(['a',True,1],index=['first','second','third'])
print(x)
#索引访问
print(x['second'])#索引名
#追加系列
n = Series(['2'], index=['fourth']) # 追加时需要指定索引
x = pd.concat([x, n])
print(x)
#判断值,数字和逻辑值是不需要加引号
print(2 in x.values)
print('2' in x.values)
#切片
print(x.loc['second':'third']) # 使用标签切片
#删除
x=x.drop("first")#索引名
print(x)
x=x[2!=x.values]
print(x)
first a
second True
third 1
dtype: object
True
first a
second True
third 1
fourth 2
dtype: object
False
True
second True
third 1
dtype: object
second True
third 1
fourth 2
dtype: object
second True
third 1
fourth 2
dtype: object
Series的sort_index(ascending=True)方法可以对index进行排序操作,ascending参数用于控制升序或降序,默认为升序。也可使用reindex方法重新排序。在Series上调用reindex重排数据,使得它符合新的索引,如果索引的值不存在就引入缺失的数据值。
from pandas import Series
import pandas as pd
obj=Series([4.5,7.2,-5.3,3.6],index=['b','d','a','c'])
print(obj)
obj1=obj.reindex(['a','b','c','d','e'])
print(obj1)
obj2=obj.reindex(['a','b','c','d','e'],fill_value=0)
print(obj2)
b 4.5
d 7.2
a -5.3
c 3.6
dtype: float64
a -5.3
b 4.5
c 3.6
d 7.2
e NaN
dtype: float64
a -5.3
b 4.5
c 3.6
d 7.2
e 0.0
dtype: float64
相关的错误点
1:对于字符或字符串型的数据要记得加上引号
2:索引的长度不能超过index的长度不然会报错
3:在追加数据时不能追加单个元素,要追加系列
4:需要一个变量来承载变化,例如在追加时需要用变量接收,即返回的是一个新的序列
特点
1:Series是一种类似于一维数组的(numpy)的对象。
2:Series的数据类型没有限制。
3:Series有索引,把索引当做数据的标签看待,类似于字典。
4:Series同时具有数组和字典的功能。
DataFrame
DataFrame数据框是用于存储多行和多列的数据集合,是Series的容器,类似于Excel的二维表格。
对于DataFrame的操作无外乎'增,删,改,查'。DataFrame使用方法如下:
from pandas import DataFrame,Series
import pandas as pd
df = DataFrame({'age':Series([26,29,24]),'name':Series(['ken','jerry','ben'])},index=[0,1,2])
print(df)
age name
0 26 ken
1 29 jerry
2 24 ben访问方式
访问列 变量名[列名] 访问对应的列。如df[name]
访问行 变量名[n:m] 访问n行到m-1行的数据。如df[2:3]访问n 1到(n 2-1)行,m 1到(m 2-1)列的数据。
访问块(行和列) 变量名. iloc[n 1:n 2,m 1:m 2] 如df . iloc[0:3,0:2]
访问指定的位置 变量名.at[行名,列名] 访问(行名,列名)位置的数据。如df . at[1,'name']
from pandas import DataFrame,Series
import pandas as pd
df = DataFrame({'age':Series([26,29,24]),'name':Series(['ken','jerry','ben'])},index=[0,1,2])
print(df)
a=df['age']
print(a)
b=df[1:2]
print(b)
c=df.iloc[0:2,0:2]
print(c)
d=df.at[0,'name']
print(d)
age name
0 26 ken
1 29 jerry
2 24 ben
0 26
1 29
2 24
Name: age, dtype: int64
age name
1 29 jerry
age name
0 26 ken
1 29 jerry
ken
功能函数
from pandas import DataFrame,Series
import pandas as pd
df = DataFrame({'age':Series([26,29,24]),'name':Series(['ken','jerry','ben'])},index=[0,1,2])
df.columns=['age1','name1']#修改列名
print(df)
df.index=range(1,4)#修改索引
print(df.index)
df=df.drop(1,axis=0)#行索引删除,axis=0表示行轴
print(df)
df=df.drop('age1',axis=1)#列名删除
print(df)
#删除列del df['age1']
df['newColumn']=[2,4]#增加列
print(df)
df.loc[len(df)]=['keno',24]#增加行
print(df)
print(len(df))
age1 name1
0 26 ken
1 29 jerry
2 24 ben
RangeIndex(start=1, stop=4, step=1)
age1 name1
2 29 jerry
3 24 ben
name1
2 jerry
3 ben
name1 newColumn
2 jerry 2
3 ben 4
name1 newColumn
2 keno 24
3 ben 4
2合并DataFrame
from pandas import DataFrame, Series
import pandas as pd
df1 = DataFrame({
'A': Series([1, 3]),
'B': Series([2, 4])
}, index=[0, 1])
print(df1)
df2 = DataFrame({
'A': Series([5, 7]),
'B': Series([6, 8])
}, index=[0, 1])
print(df2)
# 只叠加数据,但保留原始索引
df_appended_with_index = df1.append(df2)
print(df_appended_with_index)
# 合并为一个新的数据框,并忽略原始索引,创建新的整数索引
df_appended_ignore_index = df1.append(df2, ignore_index=True)
print(df_appended_ignore_index)



![[HUBUCTF 2022 新生赛]最简单的misc](https://img-blog.csdnimg.cn/direct/9f184c91bb644ac3a95d9a65d5b37bc6.png)